Branded food databases, food labelling, and reformulation

What are branded foods?
Branded foods are prepacked foods, typically equipped with a label showing information on the ingredients and the nutritional content. Barcodes are usually used as a unique identifier of specific foods.

What are branded food datasets?
Branded food datasets are very large datasets with nutrient composition and other information for tens of thousands prepacked foods. Data usually reflect information from food labels, and could be enriched with additional information. Datasets need to be updated regularly because new or reformulated foods are being launched all of time while other products are removed from the market.
Why do we need branded food datasets?
Food researchers need food label data to support food policy development. For instance, they monitor food and nutrient intake, and progress on food reformulation. Food label data is also very useful for dietitians, public health educators, mobile app developers and the food industry.
Users of branded food datasets
The aim of the “food labelling & reformulation” demonstrator is to showcase how food label data and branded food databases can be useful to a wide range of users, from researchers to policy makers, consumers, food businesses, app developers and clinical practitionners. The cases studies below illustrate differents aspects of the use of food labelling data.
Researchers
- epidemiological dietary studies (consumption)
- dietary intervention studies
- clinical intervention trials, where diet or foods are considered co-founding factors
- food supply studies assessment of exposure to food components
Assessing the validity of data in branded food datasets
Valid food composition data are needed in nutrition research, for example in studies investigating dietary intakes, where branded food datasets are becoming a particularly valuable resource. However, the question arises whether food labelling data correspond to the actual composition of the branded foods. A case study was conducted on 51 sugar-sweetened beverages in the CLAS branded food dataset, in which labelled content of sugar was verified by laboratory measurements. The study results showed that the labelled sugar content is reliable and can be used to compile branded food databases. The sugar content was within the tolerance levels in all investigated samples.
More information: Hafner et al. 2022, Front. Nutr. Doi: 10.3389/fnut.2022.794468
Policy Makers
- basis for evidence-based food policy decisions monitoring of the food supply
- assessment of efficacy of food reformulation programmes
- regulatory restrictions, related with specific food components (trans fats, additives…)
Monitoring food reformulation
Continuous food monitoring studies provide insights about the changes in the food supply, supporting the decisions of policy makers. Such monitoring can be focused on various aspects of food composition, including the content of nutrients and the use of food additives. The FNS-Cloud project used longitudinal data, originating from several cross-sectional food monitoring studies, to provide insights on food reformulation. An example of such study, which was focused on both nutritional composition and use of additives, exploited trends in the composition of non-alcoholic beverages in Slovenia. The study highlighted a sharp rise in the use of sweeteners between 2017 and 2020.
More information: Hafner et al. 2021, Front. Nutr. Doi: 10.3389/fnut.2021.778178
App Developers
- operation of IT services where branded food composition data is needed
- mobile apps and web services for supporting consumers and health practitioners (to support dietary, lifestyle and health objectives)
Consumers
- supporting and guiding informed food choices
- enabling comparison of different foods
- supporting choices of healthier foods
- assuring food safety, particularly to those with special dietary needs (including allergen management and specific diets)
Branded food datasets are a useful resource for app developers and support healthier food choices
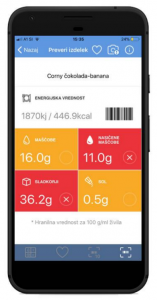 Access to reliable branded food datasets is essential for efficient functioning of mobile apps that are covering peoples diets and food choices. In the FNS-Cloud project, we used automatic data transfer through an Application Programming Interface (API) to connect the data collected in the food monitoring study with the mobile app VešKajJeš, which is used in Slovenia to support consumers in healthier food choices. Transferred data included all parameters needed for nutrient profiling in the food traffic light system (food category, the content of sugar, salt, (saturated) fat) and energy value.
Access to reliable branded food datasets is essential for efficient functioning of mobile apps that are covering peoples diets and food choices. In the FNS-Cloud project, we used automatic data transfer through an Application Programming Interface (API) to connect the data collected in the food monitoring study with the mobile app VešKajJeš, which is used in Slovenia to support consumers in healthier food choices. Transferred data included all parameters needed for nutrient profiling in the food traffic light system (food category, the content of sugar, salt, (saturated) fat) and energy value.
More information: Pravst et al. 2021, Front. Nutr. Doi: 10.3389/fnut.2021.798576
Food businesses
- identification of opportunities for improving composition of foods (development of new foods, reformulation)
- comparisons with other foods – use of comparative nutrition claims
Clinical practitionners
- nutritional counselling in patients (evaluation of intakes of foods/nutrients)
- preparation of diets for patients with special dietary needs (including allergies) or medical conditions (for example diabetes)